yuchi's Development Home
우선 먼저 포스팅한 결과에는 꽤 오류가 있었다는 점을 말해두고 싶다.
가장 큰 문제는 CPU측과 GPU측 코드의 자료구조가 다르다는 점이다.
퍼포먼스 차이를 가장 많이 갈라놓은건 자료구조의 차이였다.
CPU계산과 GPU계산을 실시간으로 전환하기 위해 코드를 수정했다. 그 결과 동일한 자료구조 동일한 상태 업데이트 코드를 가지게 되었고 결과는 상당히 달라졌다.
우선 코드가 어떻게 동작하는지 간단히 설명한다.
용어정리 :
Host = CPU와 메인보드에 꽂힌 DDR시스템 메모리.
Device = GPU와 그래픽카드 메모리.
N = CPU가 지원하는 논리 코어의 개수(i7 2600K의 경우 N은 8)
코드설명
1. 월드는 3차원 그리드로 분할된다. 현재는 그리드의 한 CELL은 1m*1m*1m의 크기를 가진다.
2. 모든 오브젝트는 매번 갱신된다고 가정한다. N개의 CPU스레드가 모든 오브젝트들을 호스트측 그리드에 업데이트한다.
3. 여기까지 CPU코드와 GPU코드 모두 동일하다.
CPU모드일경우
A. N개의 스레드에 충돌처리할 오브젝트 개수를 할당한다.스레드당 오브젝트 개수 = (오브젝트 개수 / N)
B. N개의 스레드가 할당받은 오브젝트들에 대해서 충돌계산을 한다. 그 결과도 N개의스레드가 호스트측에 바로 업데이트한다.
GPU모드일 경우
A. 충돌처리할 오브텍트들의 데이타를 Host에서 Device로 전송한다.(PCI-E버스를 타고간다)
B. 충돌처리할 오브젝트 1개는 CUDA 스레드 1개에 맵핑된다. 블럭 개수는 SM개수를 따른다.
C. CUDA커널이 호출되면 모든 스레드들이 각각 맡은 오브젝트에 대해서 충돌처리를 한다.
D. 각각의 스레드들이 Device측 결과 버퍼에 결과를 저장한다.
E. 모든 블럭의 처리가 종료되면 CPU코드에서 Device측 결과버퍼를 Host측으로 전송한다.
중간결과
이렇게 코드를 만들어놓고 테스트를 했다.
참담했다. 불편한 진실이 드러났다. CPU코드가 4-8배 빨랐다.
그 이유는...
GPU는 SIMT(Singe Instruction Multlple Threads)방식으로 작동한다.
16개나 32개의 스레드가 묶여서 한워프로 실행되는데 오브젝트 32개가 모두 동일한 상태라면야 최적의 조건이겠지만 그럴 가능성이 낮다.
예를 들어 오브젝트 A의 주변에 15개의 타원체와 12개의 삼각형이 있다. 오브젝트B의 주변에는 삼각형과 타원체가 0개이다. 오브젝트 A를 처리할때는 27번의 교차검사가 필요하다.
오브젝트 B의 경우 교차검사가 아예 필요없다.
오브젝트 B를 담당한 스레드 1은 빨리 끝내고 다음 오브젝트를 처리하면 좋겠지만 SIMT방식이기 때문에 A를 맡은 스레드0이 작업을 완료하기 전까지 아무것도 할 수 없다.
이런식으로 스레드가 32개씩 묶여있으니 오브젝트가 많아질수록 거의 병렬화의 의미가 없어지는 것이다.
그래서 전략을 바꿨다.
<블럭하나에 오브젝트 하나를 맵핑하고 블럭 내의 스레드들이 최대한 협력해서 오브젝트 한개를 빨리 처리하도록 한다.>
동시에 처리할 수 있는 오브젝트 개수는 줄겠지만 거의 모든 SP자원을 사용할 수 있을것이다. 전체적으로는 빨라지겠지.
다음과 같이 수정했다. 먼저 코드와 A,E항목은 같다.
B,C,D가 바뀌었다.
GPU모드일 경우
A. 충돌처리할 오브텍트들의 데이타를 Host에서 Device로 전송한다.(PCI-E버스를 타고간다)
B. 충돌처리할 오브젝트 1개는 8*8스레드를 가지는 1개의 블럭에 맵핑한다. 4096개의 오브젝트가 있다면 4096블럭이다.
C. CUDA커널이 호출되면 각 블럭내의 0번 스레드들이 컨트롤을 담당한다. 루프를 더 돌지 빠져나갈지를 결정하거나 쉐어드메모리의 초기화등을 한다. 블럭 내의 모든 스레드들이 오브젝트 주변의 삼각형과 다른 타원체들에 대해서 동시에 교차검사를 실시한다. 중간중간 컨트롤을 위해 0번 스레드만 활성화된다.
D. 오브젝트 1개당 충돌처리가 끝나면 0번 스레드가 Shared Memory에 저장한 충돌처리 결과를 Device측 결과버퍼에 저장한다.
E. 모든 블럭의 처리가 종료되면 CPU코드에서 Device측 결과버퍼를 Host측으로 전송한다.
이렇게 코드를 수정하고나서 CPU코드가 GPU코드보다 2-4배 빨랐다. 이전보단 좋아졌지만 아직 부족하다.
뭐가 문제일까.
코드를 수정하면서 블럭 내의 Shared Memory를 꽤 사용했다.
NV GPU는 SM하나당 16KB Cache 48KB Shared Memory를 가지고 있다.
이론상 SM한개당 8개의 블럭을 동시에 맵핑해두고 처리할 수 있다. 그런데 동시처리라는게 어차피 시분할이라 각각 블럭의 상태를 유지해두고 있어야한다. CPU라면 메모리에다가 컨텍스트를 저장해두지면 GPU는 훨씬 단순하다. 레지스터 개수가 많으니까 그냥 각각의 스레드들이 레지스터를 따로 쓴다. Shared Memory사용량이 0인 경우는 레지스터 개수에만 신경쓰면 된다.
그런데 Shared Memory를 사용하게 되면 이 역시 컨텍스트 스위칭 대상이라 사용량에 신경을 써야한다.
Shared Memory는 SM당 한개씩 있고 블럭은 SM에 맵핑된다.
곧 동시 실행 가능한 블럭의 수는 48KB / (블럭당 사용하는 Shared Memory 사이즈) 이다.
처음에는 블럭당 Shared Memory 사용량이 28KB정도였다. 48/28 = 1.xxxx니까 SM당 1개의 블럭밖에 실행하지 못한다.
코드를 잘 분석해보니 Shared Memory에 잡은 변수와 배열들중 전반부에 사용하고 후반에 사용 안하는 놈들이 있었다.
그래서 얘네들을 union으로 묶었다.
여차저차 Shared Memory사용량을 블럭당 9KB정도로 줄이고나니 GPU코드의 성능이 CPU코드의 성능을 앞섰다.
48/9 = 5.xxx이므로 SM당 5블럭을 실행할 수 있게 되었다. SM당 5개의 오브젝트를 처리할 수 있게 된 것이다.
이후로 언롤링등을 했지만 주로 Shared Memory사용량을 줄일 수 있는 방법으로 최적화를 진행했다.
우여곡절을 겪으며 최종적으로 블럭당 Shared Memory사용량을 8KB이하로 줄였다.
SM당 6개의 오브젝트를 처리할 수 있게 되었고 성능이 더 향상되었다.
성능테스트
이번 테스트에선 19440개의 삼각형을 가지는 운석맞은 크레이터같은 지형을 맵으로 사용했다.
랜덤하게 크기가 다른 타원체 오브젝트 약4000개를 집어넣었다.
여건상(귀차니즘) GTS450그래픽 카드는 PCI-E 4x슬롯에서 테스트할 수 밖에 없었다. 어차피 전송량이 많지는 않으므로 큰 차이는 없을거라 생각한다.
| Device | SP per SM | SM | Core | Bus | Time(ms) | 비고 |
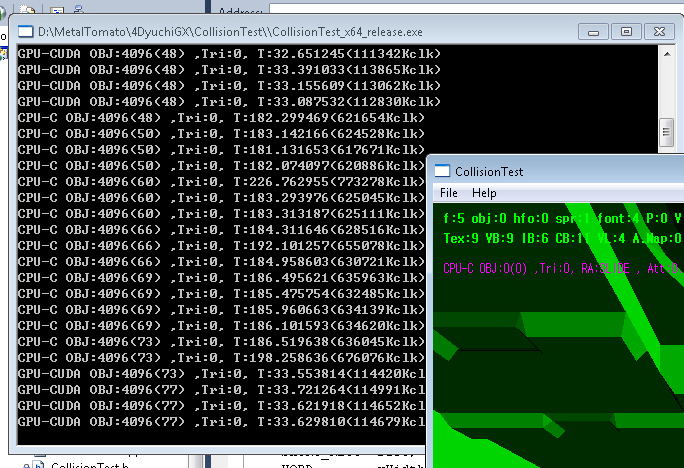
| GTX480 | 32 | 15 | 480 | 384bit | 33ms | PCI-E 16x |
| GTX460 | 48 | 7 | 336 | 256bit | 75ms | PCI-E 16x |
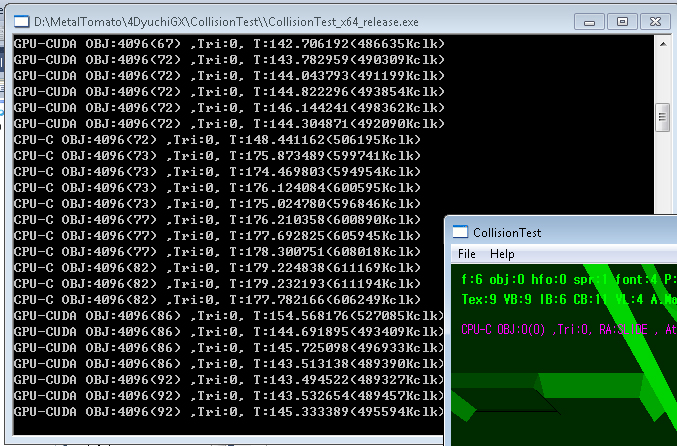
| GTS450 | 48 | 4 | 192 | 128bit | 143ms | PCI-E 4x |
| intel i7 2600K | NA | NA | 4 | NA | 182ms | TurboBoost 4Core 3.8Ghz |
스크린샷
렌더링이 테스트에 영향을 미치지 못하도록 렌더링을 중지시키고 측정값은 텍스트로 출력시켰다.
GTX460테스트시의 스샷은 찍지 못했다.
테스팅 조건
GTS450 vs i7
GTX480 vs i7
결론
물론 여기까지의 결론이다. 앞으로 또 작업내용이나 테스팅 결과에 있어 변동이 있을 수 있다.
이 프로젝트의 목적 자체가 MMROPG게임의 서버에서 충돌처리를 값싸게 구현하는것이다.
현재까지 측정 결과로 볼 때 GTX460정도의 성능을 CPU로 구현한다면 6코어 제온 2개를 꽂으면 될것 같다.
2.66GHz짜리 웨스트미어 제온2개를 구입하는데 CPU값만 300만원이 넘게 든다. GTX460 그래픽 카드는 20만원 정도다.
GTX480정도의 성능을 구현하려면 4코어나 6코어 제온을 4개 꽂으면 될것 같다. 여기서부턴 가격이 천단위로 넘어간다.
CPU 4개 꽂히는 메인보드는 일반 판매가 되지 않으므로 메이커 서버를 사용해야한다. 예전에 HP에서 견적을 내보니 4코어 4개 꽂은 서버가 25000달러였다.
가격대 성능비로 꽤 매력이 있다.
프로그래밍과 디버깅의 어려움이 있긴 하지만 초반에만 조금 고생하면 유지보수는 어렵지 않다.
GPU의 코어 수 증가는 CPU에 비해 훨씬 가파르게 올라가고 있다.
CUDA코드는 상대적으로 저렴하고 빠른 속도로 발전하는 GPU자원를 쉽게 활용할 수 있다.
새로운 GPU가 나와도 기존 코드를 그대로 사용할 수 있고 최적화를 고려해도 코드를 많이 수정할 필요는 없다.
초기 시간과 노력을 감수할 수 있다면 CUDA코드를 가지고 있다는 것은 꽤 든든한 옵션이다.
다만 무조건 GPU에 맞추는 것은 아직까진 너무 리스크가 크다고 생각한다.
CPU코드를 먼저 만들어두고 GPU버젼을 만들어 유지하는 것이 적절한 선택이라고 본다.
코드 튜닝과 성능 테스트는 일단 이것으로 일단락 짓는다..........이제 취업해야지.

정말 수고하셨습니다.
가격도 가격이지만 TDP까지 고려해보면, 서버의 남는 PCI-Ex 슬롯을 GPU로 활용하는 것이 정말 좋은 선택으로 느껴집니다.
개인적으로는 서버의 주 업무인 패킷 처리에 GPGPU를 활용해보는 것은 어떨까 하는 생각도 듭니다. (물론 잘 모르고 하는 소리입니다만...T_T)