yuchi's Development Home
충돌처리 엔진 성능을 개선해볼까 하고 테스트를 좀 해봤다.
똑같은 알고리즘을 사용하는 float3 normalize함수를 normal c , SSE Compiler Intrinsic, SSE Assembly Code로 작성해서 100만번 돌린 시간을 비교했다.
일단 짚고 넘어가야할 것은 x64에선 C로만 작성해도 SSE가 무조건 활성화된다. 즉 float연산은 xmm레지스터와 sse명령으로 실행한다. 단 벡터라이즈는 해주지 못한다. addss등 싱글 연산 명령만을 사용한다.
그러니까 엄밀히 따지면
- C로 짠 SSE Single Data Instruction
- Compiler Intrinsic으로 짠 SSE Multiple Data Instruction
- 순수 ASM으로 짠 SSE Multiple Data Instrction
의 비교다.
---------------------------------------------------------------------
[테스트 결과]
---------------------------------------------------------------------
테스트 CPU : 샌디브릿지 i7 @4.2GHz CPU .
---------------------------------------------------------------------
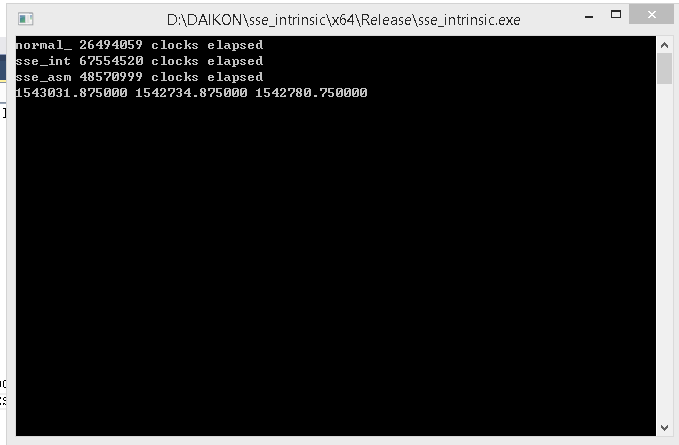
- Normal C SSE Single Data Instruction 26494059 clocks
- Compiler Intrinsic Multiple Data Instruction 67554520 clocks
- pure asm SSE Multipld Data Instruction 48570999 clocks
---------------------------------------------------------------------
보면 C코드로 작성한 SSE Single Data Instruction이 제일 빠르다.
비슷한 경우는 전에도 본적이 있어서 크게 놀라진 않았다. 다만 Compiler intrinsic을 사용한 SSE코드가 제일 느린건 놀랐다.
'SSE Instruction 사용안함'으로 체크하고 32비트 바이너리로 빌드해서 비교해보면 C코드가 가장 느리다. FPU로 연산하는건 SSE보단 확실히 느리다.
거듭 강조하지만 "C로 짠게 제일 빨라요"가 아니다.
이 테스트에서 SSE Single Data Instruction만으로 연산하는게 SSE Multiple Data Instruction으로 연산하는것보다 빨랐다는 것이다.
예전에 N사에서 게임영상 캡쳐해서 실시간으로 h264로 인코딩하는 코드를 짰었는데 그때 rgb-> yuv로 컨버팅 하는 코드를 위와 같이 세가지 버전으로 작성했었다.
그때도 동일한 결과가 나왔었다. SSE Multiple Data Instruction 최대한 이용해서 네 픽셀씩 한꺼번에 처리했는데 결과적으로 C로 짠 SSE Single Data Instruction만 사용하는 코드보다 느렸다. 물론 그때도 FPU만 사용하는 코드가 제일 느렸다.
내가 SSE에 심취해있던 2002 - 2006년까지만해도 분명히 SIMD쓴게 빨랐던걸로 기억하는데. CPU 아키텍쳐가 많이 바뀌어서 그런가?
SSE의 SIMD를 잘 써서 더 빠를 상황이 있긴 할텐데 생각보다 별로네.
하여간 코드레벨 최적화는 일단 보류다.
정말 서버비용 아끼려면 CUDA로 돌려야 할지도.
